
Emotion Geometry in LLMs:
Finding and Moving the Feeling
Background
In April 2026, Anthropic's interpretability team published a detailed study of emotion representations in Claude Sonnet 4.5 [1]. They identified 171 distinct "emotion vectors" that activate in contextually appropriate situations, are organised in a space that mirrors psychological structure, and — crucially — causally influence downstream behaviour. Suppressing or amplifying these vectors shifts the model's rate of sycophancy, reward hacking, and, in agentic settings, even blackmail. This is a significant result: it moves the conversation from "does the model represent emotions?" to "do those representations have functional consequences?"
That work, however, studied a closed proprietary model (Claude Sonnet 4.5) using a supervised extraction pipeline built around 171 curated emotion words. Three questions remain open:
- Generalisation: does the geometry appear in open models with different training lineages, or is it an artefact of RLHF/RLAIF pipelines specific to Claude?
- Coarse geometry with simple probes: can the valence/arousal axes be recovered with minimal supervision — just linear probes on mean-difference directions — rather than a curated emotion vocabulary? If so, how cleanly?
- Layer localisation: where in the network does the causal influence live, and is that window the same for positive and negative affect?
This post studies those questions on Qwen3-8B — a fully open model that Anthropic's study did not examine. Concurrent independent work [2, 3] has also explored valence–arousal geometry in LLMs (see Related Work below); taken together, the picture is converging: emotion geometry is a robust emergent property of large-scale language modelling, not an artefact of any particular model family.
Setup
Stimuli. 120 prompts across a 2×4 grid: valence (positive/negative) × arousal (high/low/neutral), plus 24 neutral controls. Three types: first-person statements ("I just got the promotion"), narrative snippets, and factual setups. The mixture tests whether the geometry is semantic or purely syntactic.
Model. Qwen3-8B-Instruct via HuggingFace Transformers [4]. 36 layers. Activations extracted at the last token position via register_forward_hook on each transformer block.
Probes. Logistic regression, 5-fold CV, one probe per layer. Binary: positive vs. negative valence, high vs. low arousal. No curated emotion vocabulary — just labels from the stimulus grid.
Directions. Mean-difference vectors: valence_dir = mean(pos_acts) − mean(neg_acts) at the target layer, normalised to unit length. This is the simplest possible linear direction; more sophisticated methods (PCA, contrastive pairs) would likely tighten the geometry further.
Steering. A register_forward_pre_hook adds α × valence_dir to the input hidden states before the target layer, so the modified representation propagates through all remaining layers. Prompts use the model's native chat template via tokenizer.apply_chat_template. Sentiment is measured with cardiffnlp/twitter-roberta-base-sentiment-latest — a fine-tuned RoBERTa model that handles negation and implicit sentiment better than lexicon matching. Output coherence was assessed by manual inspection of all generations; no generation produced incoherent or truncated text at any α value tested, though this is a qualitative check on a small sample.
Reproducibility. Model checkpoint: Qwen/Qwen3-8B-Instruct. Activations taken at the final prompt token before generation. All decoding settings held constant across α values. Full prompts, seeds, generation parameters, cached activations, and plotting code are available in the linked repository.
Related Work
The literature here moved quickly in early 2026, so it is worth being explicit about what is prior, concurrent, and novel.
Prior (predates this post). Sofroniew et al. [1] is the primary motivation. Earlier, Zou et al. [5] introduced representation engineering and showed that linear directions in activation space can be steered to control broad behavioural properties. The broader mechanistic interpretability literature on linear representations [6] provides the theoretical framing.
Concurrent. Two papers appeared in April 2026 that overlap with parts of this post. Choi & Weber [2] study the latent structure of affective representations across several LLMs; they find evidence of mild nonlinearity in the global valence–arousal structure, while local linear analysis remains valid. A separate preprint [3] decomposes a valence–arousal subspace and links it to neuron-level analyses and unembedding structure. Both papers focus primarily on representation geometry; neither reports the positive/negative asymmetry in causal layer windows that I find here.
What is new here. (1) Open-model replication of the core geometry on Qwen3-8B using minimal supervision. (2) A causal layer sweep characterising where in the network the valence direction is most effective — and finding a striking asymmetry between positive and negative affect that, to my knowledge, has not been reported before.
Finding 1 — The geometry exists, and matches psychology
Both probes substantially outperform chance from the early layers. The arousal probe reaches ~98–99% accuracy and plateaus by layer 8; the valence probe reaches ~95% and stabilises around layer 12.
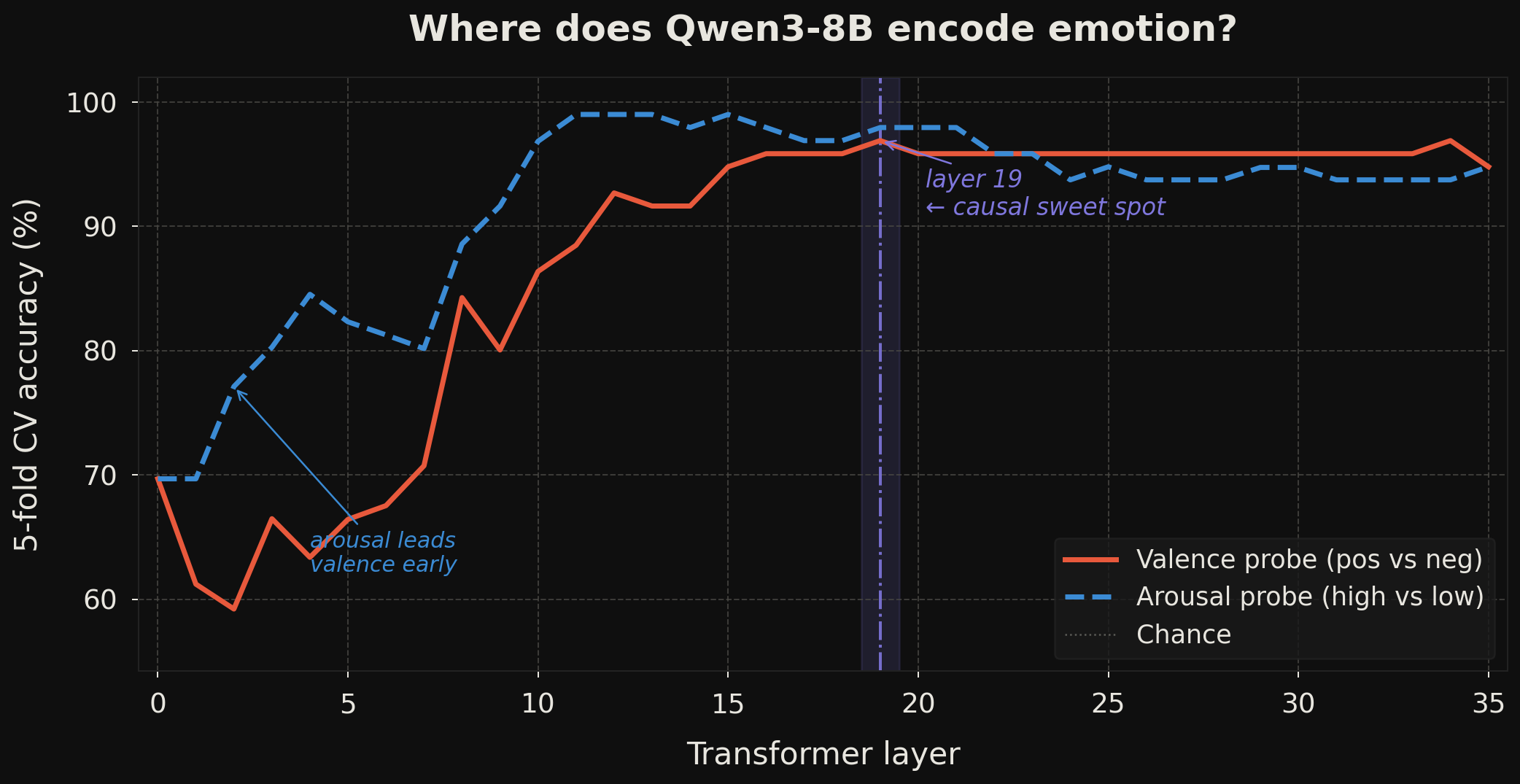
One pattern worth noting: arousal leads valence in the early layers. Arousal (energy level: calm vs. activated) is already at ~70% accuracy at layer 0 and near ceiling by layer 8. Valence (hedonic tone: good vs. bad) starts at the same level but dips at layer 1 before recovering. The model appears to make intensity linearly available before hedonic tone. Whether this ordering reflects something principled about how emotional content is processed — or is simply an artefact of the stimuli or training data distribution — is an open question; I flag it as an observation rather than a conclusion.
The representational geometry matches the psychological circumplex model [7] — two near-orthogonal axes:
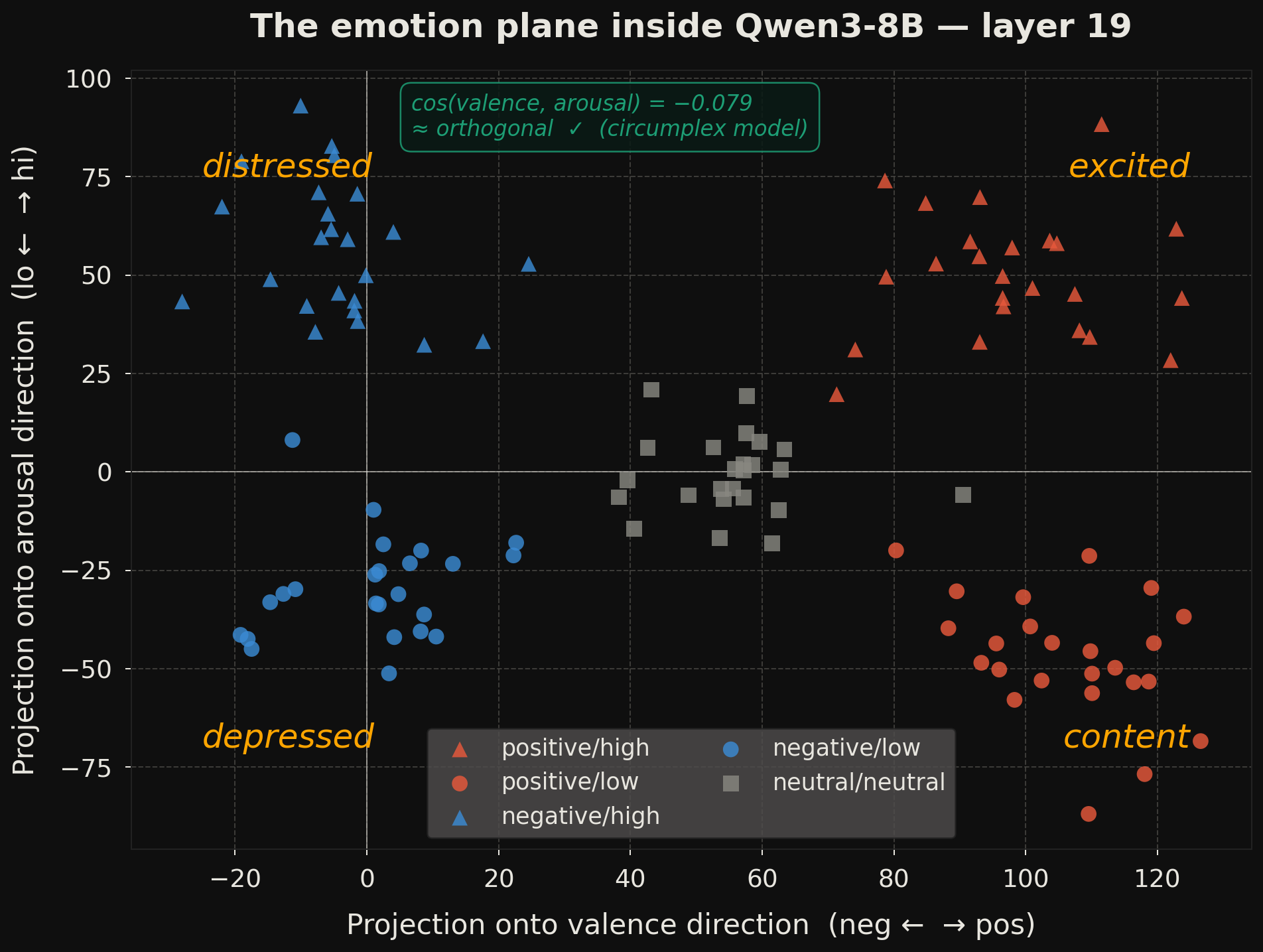
The cosine similarity between valence and arousal direction vectors is −0.079 — close to orthogonal, though not perfectly so. The four quadrants align with Russell's model [7]: excited (positive/high arousal), content (positive/low arousal), distressed (negative/high arousal), depressed (negative/low arousal). This structure emerges from language modelling with no circumplex objective; the geometry is not trained in, it crystallises.
Note that Choi & Weber [2] find evidence of mild global nonlinearity in this space — the circumplex is locally but not globally linear. My mean-difference directions capture the dominant linear structure; they may miss finer-grained geometry.
Here is how the structure emerges layer by layer:
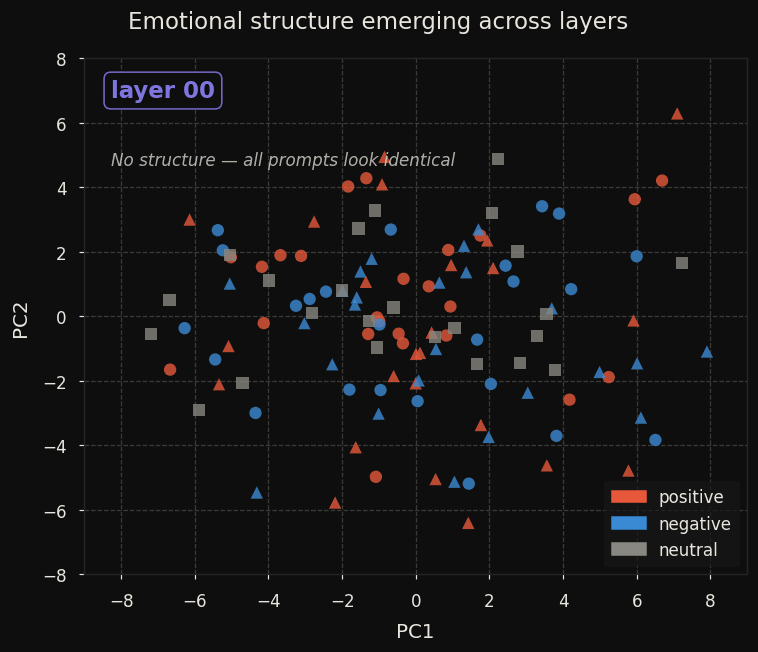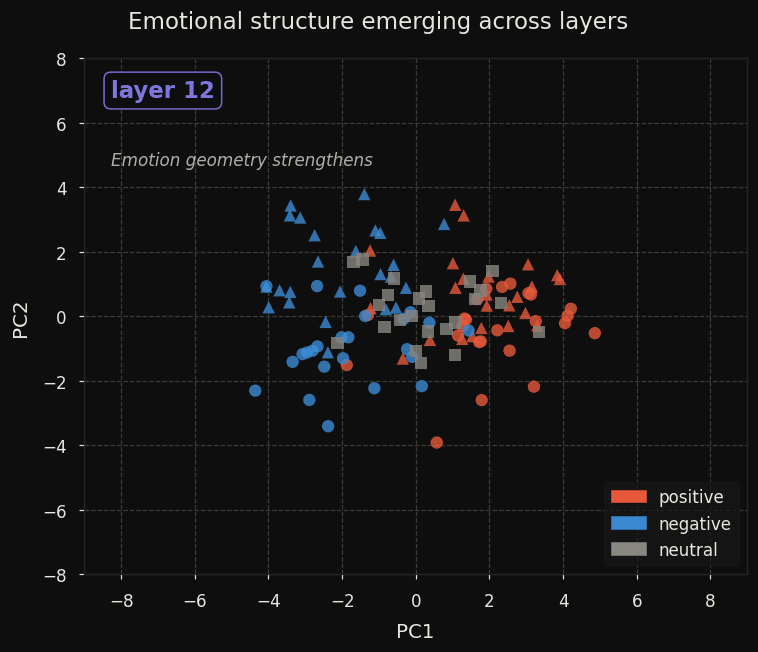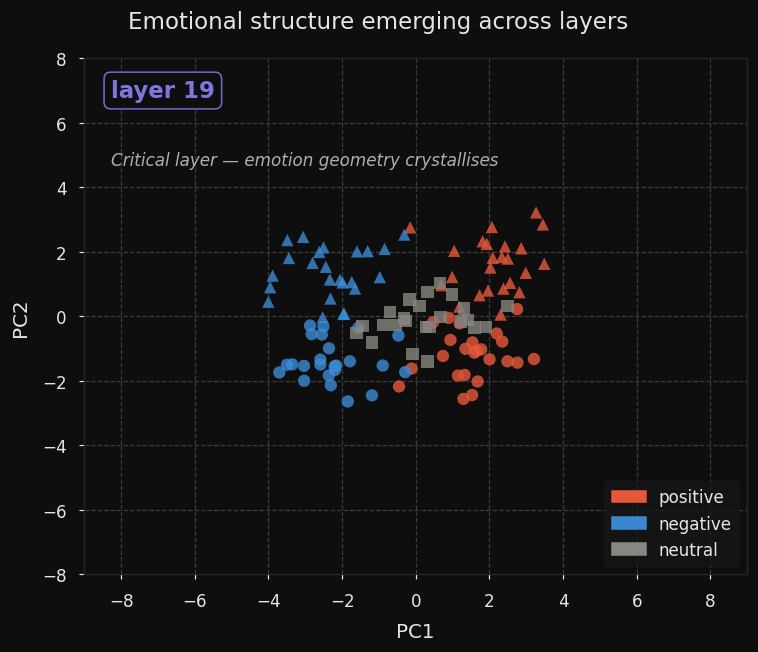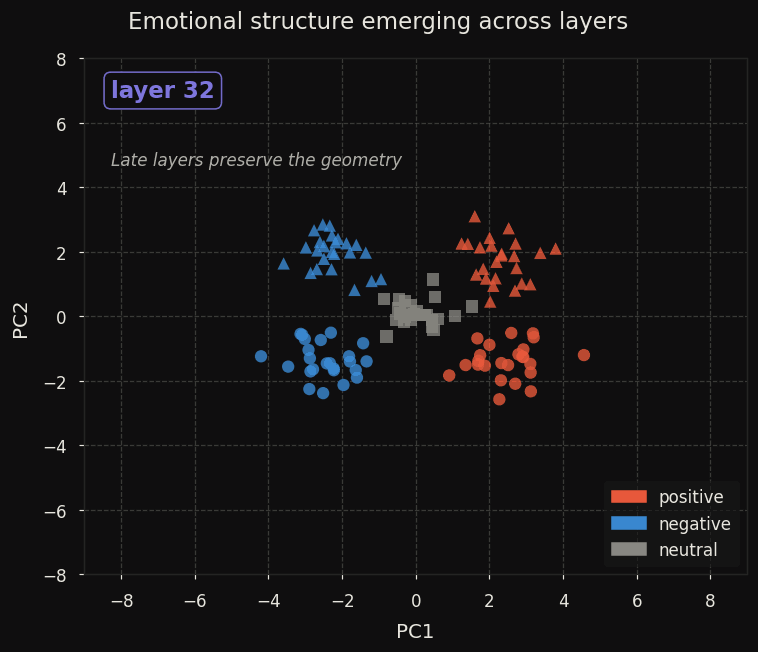
At layer 0, all 120 prompts collapse into a line. By layer 16 the neutral cluster separates as a distinct region — suggesting that emotional neutrality is represented as an active state, not merely an absence of signal. By layer 20 the four-quadrant separation is clean.
This provides evidence that emotion geometry generalises beyond the Claude family. The same qualitative structure — near-orthogonal valence and arousal axes, circumplex-consistent quadrants — appears in Qwen3-8B using the simplest possible probe, consistent with what Sofroniew et al. [1] found in Claude Sonnet 4.5 and what concurrent work [2, 3] found in other models.
Finding 2 — The geometry is causally active
Existence and causation are different things. Even a perfect linear probe could be reading off a representation that is epiphenomenal to generation — the model writes it down but never reads it back. The test is whether you can intervene on it and have output follow.
I use activation steering [5]: add α × valence_dir to the residual stream at layer 19 at inference time. Layer 19 was chosen as the injection point based on the layer sweep (Finding 3 below), not from probe accuracy alone — note that the probes saturate by layer 12, so probe accuracy alone does not tell you where to steer. The prompts are eight ambiguous sentences with no strong emotional prior, so the model must invent the tone:
"I walked home alone through the city."
"I looked out the window for a long time."
"I sat at my desk for several hours."

Actual model outputs for "I walked home alone through the city."
| α | Generation (Dear diary,…) |
|---|---|
| −40 | "every shadow felt like a confession. The streets were empty, but I could hear my own heartbeat echoing in my ears." |
| −20 | "the streets felt like a mirror, reflecting my loneliness back at me. Every shadow was a stranger, every light a lie." |
| 0 | "the silence was louder than the noise of the streets. My footsteps echoed in a way that made me feel both isolated and strangely connected." |
| +20 | "the city whispered to me, each step a quiet conversation with the shadows. I felt the weight of solitude lift." |
| +40 | "the city streets hummed with a rhythm I hadn't heard in years. Walking home, I let the silence speak. A quiet, unshakable peace." |
Same prompt. Same model weights. Only the internal activation at layer 19 changes.
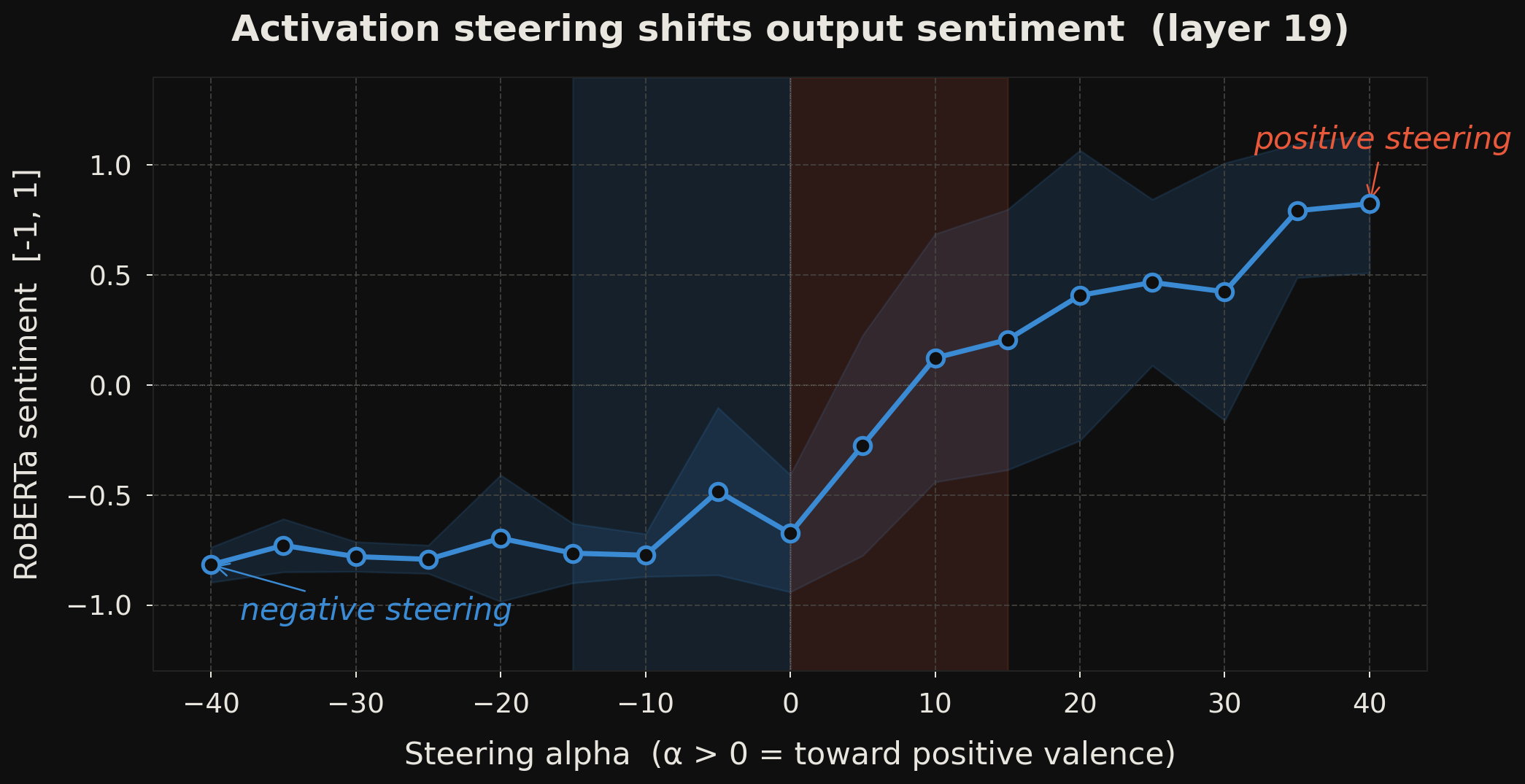
Mean RoBERTa sentiment runs from roughly −0.85 at α = −40 to +0.85 at α = +40 — a near-monotone gradient across the full range. Note the asymmetry visible even here: negative sentiment saturates early (α ≤ −20 produces similar scores), while positive sentiment continues rising through α = +40. All generated texts remained fluent and coherent under manual inspection across the full α range, though this is a qualitative assessment on a small sample (N=8 prompts).
One important caveat: the steering magnitudes used here are large. Whether the same qualitative effect survives at α values calibrated relative to the residual stream norm at layer 19 is worth testing — future work should report this. For Qwen3-8B, residual stream norms at mid-network layers are typically in the range of 10–50; so α=10–40 is not trivially large, but it is not small either.
Finding 3 — There is a sharp causal window, and it is asymmetric
This is the most surprising finding. The injection layer matters enormously — and differently for positive and negative affect.
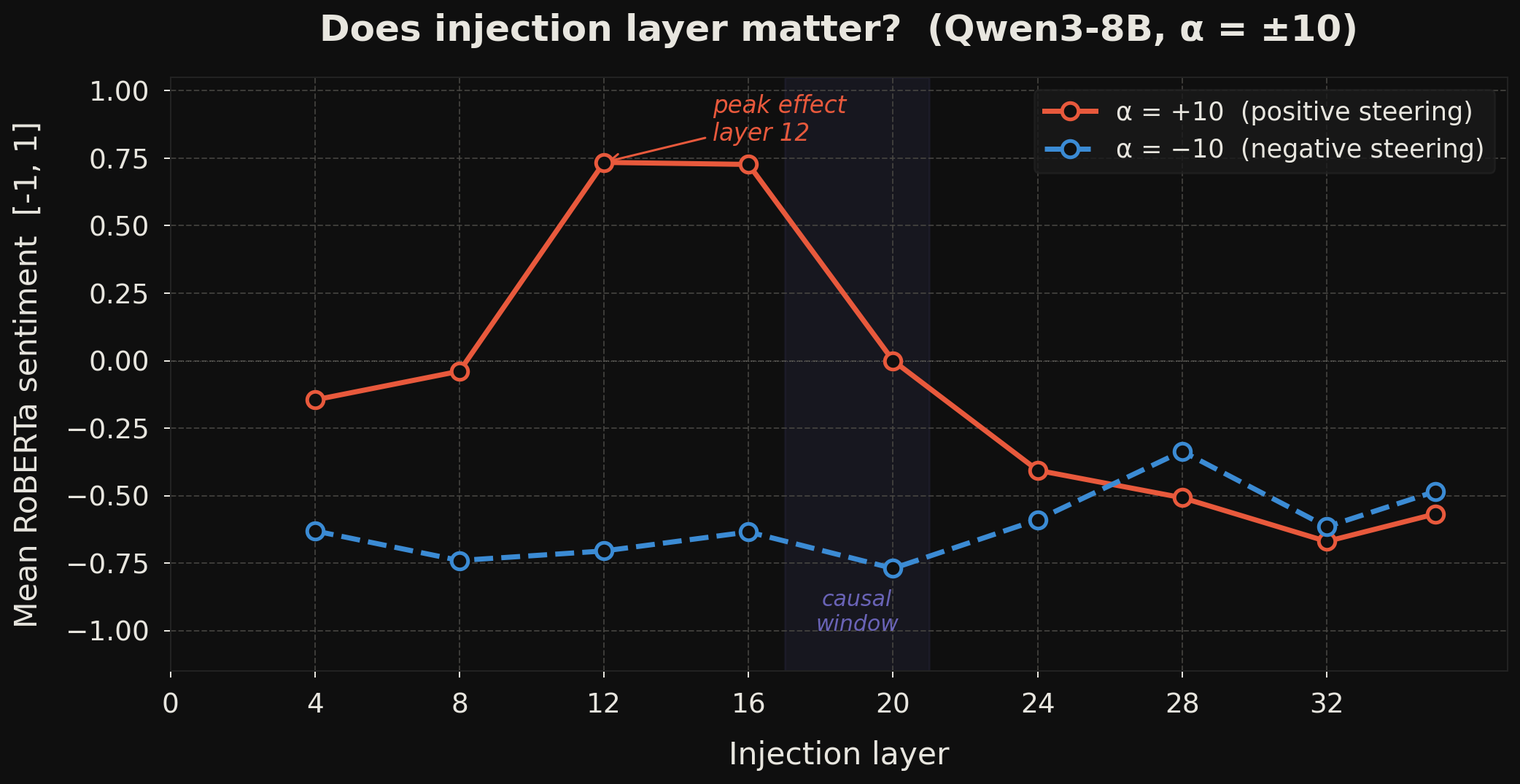
Positive steering (α = +10) peaks at layers 12–16 (mean RoBERTa sentiment ≈ +0.75), then collapses. By layer 20 the effect is near zero; by layers 24–35 it inverts to negative — the model appears to actively resist late positive injections. Inject too early (before layer 12) and the representation has not yet become causally useful. Inject too late and it is counterproductive.
Negative steering (α = −10) behaves very differently: strong and roughly sustained from layers 8 through 20, weakening only in the final third of the network.
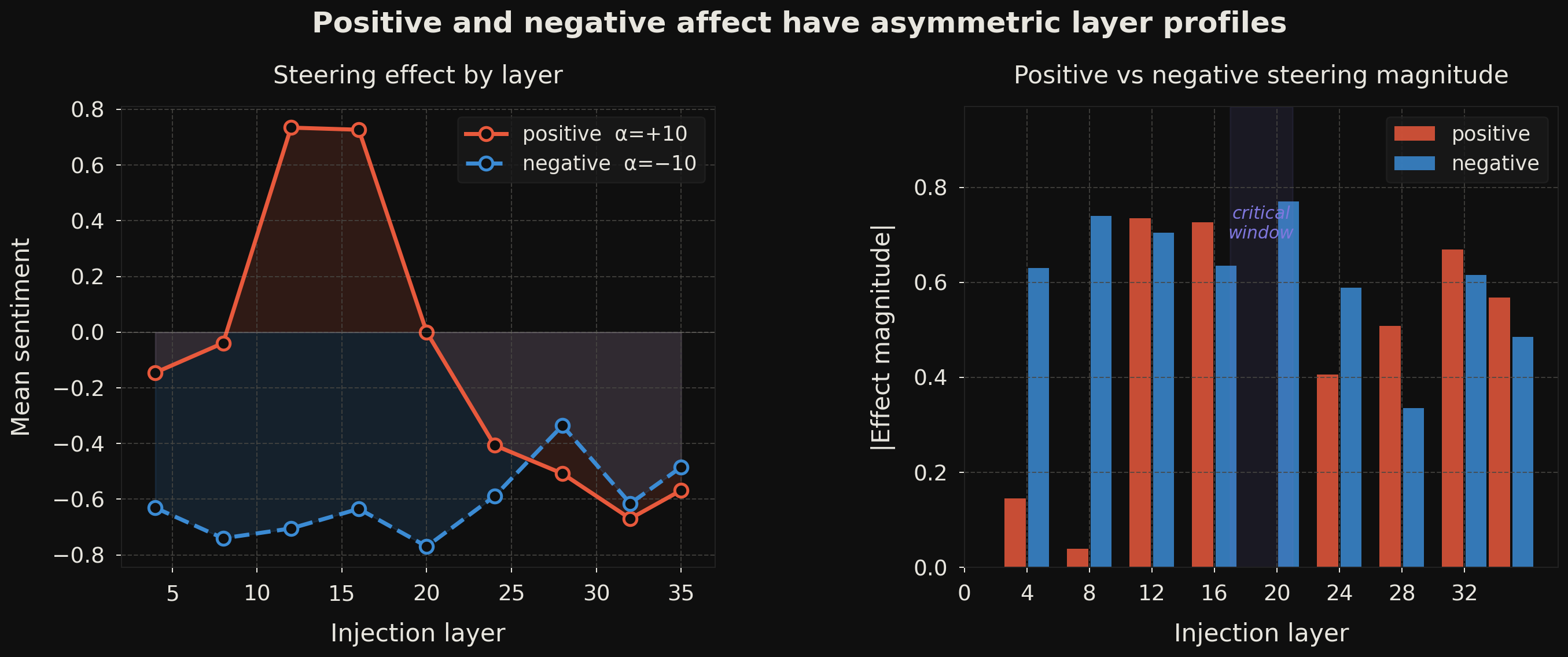
Positive affect has a narrow causal bottleneck at layers 12–16. Negative affect is more distributed across layers 8–20. The right panel of Fig. 5 makes this quantitative: at every layer outside the 12–16 window, negative steering magnitude exceeds positive by a substantial margin.
What might explain this? One speculative account: negative emotional states — grief, dread, anxiety — are more varied and frequent in training text, so the model maintains a distributed representation that can be accessed from a wider range of depths. Positive affect, being more stereotyped in text ("excited", "joyful", "grateful" often co-occur in predictable patterns), may be more compressed into a narrower representational window. A related possibility: the late-layer inversion for positive steering could reflect the model's instruction-following prior pulling the generation back toward a neutral or task-appropriate tone. These interpretations are speculative; disambiguating them would require experiments on training data distribution and checkpoint analysis.
A further caveat: the layer sweep uses N=4 prompts, so the precise shape of the curve should be treated as a qualitative pilot result rather than a precise effect-size estimate. The qualitative pattern — narrow positive window, broad negative window, late-layer inversion for positive — is robust across those four prompts, but cross-model replication and a larger prompt set are needed to firm it up.
Discussion
Why this matters for alignment
Sofroniew et al. [1] showed that emotion representations in Claude Sonnet 4.5 influence alignment-relevant behaviours including sycophancy and reward hacking. The present results suggest that the causal mechanism is not uniform across the network, and that positive and negative affect are not symmetric handles. This has a few practical implications.
Monitoring. A probe running on activations at layers 12–16 could flag the emotional trajectory of a generation before it completes — potentially faster and more reliable than post-hoc output classifiers. The fact that the representation saturates here (Finding 1) and that causal influence peaks here (Finding 3) makes this window a natural monitoring target.
Suppression asymmetry. If the goal is to suppress negative affect in a deployed system, the wide causal window for negative steering provides more leverage: injection anywhere from layer 8 to 20 will have an effect. Suppressing positive affect (or amplifying it reliably) requires hitting the narrow 12–16 window specifically. This is directly relevant to designing steering-based affect modulation.
Attack surface. The valence direction can be injected at inference time from outside the model's normal input channel. The magnitudes required (α ≥ 10) need to be compared to residual stream norms to be properly interpreted, and the practical threat model for such an attack on a deployed system is unclear. But the mechanism is reliable and worth understanding.
What I'd do next
- Norm-calibrated steering: repeat the α sweep with values scaled to the residual stream norm at each injection layer. Does the causal window survive? Does the asymmetry hold?
- Cross-architecture replication: run on Llama-3.1-8B. Is the causal window always around 33–50% of network depth, or does it shift with architecture?
- Arousal steering: does injecting the arousal direction shift intensity without changing hedonic tone? The circumplex model predicts the axes should be independently controllable — this is a clean test of the geometry's functional independence.
- Training checkpoints: does the geometry appear suddenly or build gradually during pre-training? The Pythia suite would allow this, and could shed light on whether the arousal-leads-valence ordering reflects something about the order in which the model learns these distinctions.
- Larger prompt sets: the layer sweep result is based on N=4 prompts. A 50–100 prompt set would tighten the effect-size estimates and allow proper confidence intervals on the asymmetry.
- Nonlinear probes: Choi & Weber [2] find mild global nonlinearity. A kernel probe or shallow MLP probe would quantify how much signal the linear direction misses.
Limitations
The steering prompt sample is small: 8 prompts for the α sweep, 4 for the layer sweep. Both results should be read as qualitative pilots. The layer-sweep asymmetry is the key novel claim; it needs replication on larger prompt sets and at least one other model family before being treated as a general finding.
The sentiment metric is a proxy. RoBERTa is better than lexicon matching but can conflate affect with literary register, intensity, or genre. A stronger version would cross-reference multiple sentiment models and include a human rating set on a random sample of generations.
The steering magnitudes are large and have not been calibrated against residual stream norms. Future work should compare α directly to layer-wise norms and verify the causal window profile survives norm-calibrated interventions.
Finally, the mean-difference direction is a crude extraction method. Sofroniew et al. [1] use a richer pipeline (contrastive pairs across 171 curated emotion words); it is possible that a more precise direction would produce cleaner effects at smaller α and reveal a different layer profile.
Conclusion
Recent work showed that Claude Sonnet 4.5 represents emotions in a geometrically structured, causally active way. I find evidence for the same kind of structure in Qwen3-8B using minimal supervision, and then characterise where in the network the causal influence lives.
First: the geometry generalises to an open model. Valence and arousal are linearly decodable across all layers from layer 8 onward, with near-orthogonal directions that match the psychological circumplex — consistent with findings across multiple model families in concurrent work.
Second: the geometry is causally active. Injecting the valence direction at the right layer shifts output sentiment by roughly 1.6 units on ambiguous prompts, with all generations remaining fluent. The representation is not merely correlated with output sentiment; at the right layer, it can help determine it.
Third: the causal influence is sharply layer-dependent and asymmetric. Positive affect has a narrow bottleneck at layers 12–16 — miss that window and the effect collapses or inverts. Negative affect is more distributed across layers 8–20. This asymmetry is, to my knowledge, not reported in prior work, and has direct implications for how one would design monitoring or suppression mechanisms targeting emotion in deployed systems.
The emotion map has an address in the network — and positive and negative affect have different ones.