
Mood Vectors in Audio Diffusion:
Steering Stable Audio 3
register_forward_hook silently fails on @torch.compiled blocks — method monkey-patching is the fix, and it's not documented anywhere.
Motivation
Anthropic's recent work on emotion representations in Claude Sonnet 4.5 [1] showed that emotion vectors are causally active — suppressing them shifts alignment-relevant behaviours including sycophancy and reward hacking. My previous post replicated the geometric structure in Qwen3-8B and found a sharp positive/negative asymmetry in causal layer windows.
The natural next question: does the same kind of linear structure appear in generative audio models? Stable Audio 3 is architecturally different from a language model — it generates continuous waveforms through iterative denoising, not next-token prediction — yet its backbone is still a Transformer operating on a residual stream. If the linear representation hypothesis holds broadly across modalities, mood should be recoverable somewhere in that stream.
This post tests that hypothesis on the freshest possible target: Stable Audio 3 medium, released by Stability AI in May 2026 [2].
Stable Audio 3
Stable Audio 3 is a latent diffusion model for variable-length audio generation released by Stability AI in May 2026 [2]. Its architecture has three components:
- SAME (Semantic-Acoustic autoencoder) — encodes 44.1 kHz stereo audio into a compact latent space, 852M parameters.
- DiT (Diffusion Transformer) — a 24-layer ContinuousTransformer on the latent space, conditioned on text via cross-attention to T5Gemma and on duration via adaptive layer norm. d_model = 1536.
- Decoder — reconstructs waveforms from denoised latents.
I use stable-audio-3-medium (1.4B DiT parameters, open weights). The residual stream has dimension 1536 across 24 transformer blocks.
The @torch.compile Problem — Read This First
This section comes before the method because it affects everything downstream. SA3's TransformerBlock is decorated with @torch.compile. Standard register_forward_hook calls fire on the compiled output but do not modify the actual computation — the traced graph has already been fixed, and hooks run on a copy that is discarded. My initial steering had zero perceptible effect even at α = 100.
The solution is to monkey-patch the block's forward method directly:
original_forward = block.forward
def patched_forward(*args, **kwargs):
out = original_forward(*args, **kwargs)
vec = mood_vector.to(out.device, out.dtype)
return out + alpha * vec.unsqueeze(0).unsqueeze(0)
block.forward = patched_forward
# ... generate ...
block.forward = original_forward # restoreThis replaces the bound method so the modification propagates through the compiled graph. The same pattern applies to any @torch.compiled model where you want to intervene on intermediate activations. I found no documentation of this issue in the existing mech interp literature for audio models — flagging it here for anyone who hits it.
Method
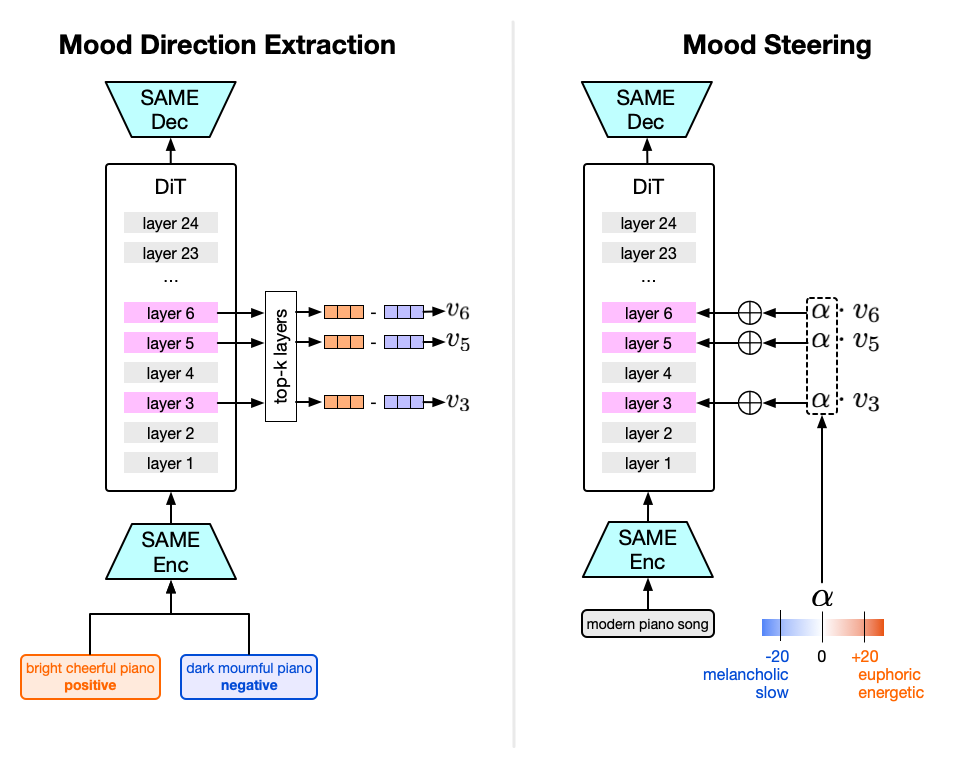
Mood vector extraction
I construct 50 contrastive prompt pairs — one with positive valence, one with negative — with musical genre held constant to isolate mood from style. Ten genres are covered (piano, acoustic guitar, jazz, electronic, strings, ambient, rock, folk, lo-fi, cinematic), 5 pairs each. Example pair:
"a bright cheerful acoustic guitar fingerpicking in a major key"
"a dark and lonely acoustic guitar fingerpicking in a minor key"
For each pair, both prompts run through SA3 with forward hooks on all 24 DiT blocks. The mood direction at layer l is the unit-normalised mean-difference vector:
v_l = mean(acts_positive) - mean(acts_negative)
v_l = v_l / torch.norm(v_l) # unit normaliseThis is the same extraction method used in my LLM emotion post and in standard representation engineering [6]. It is intentionally minimal — no curated emotion vocabulary, no contrastive activation addition training, no SAE. The goal is to ask how much mileage you get from the simplest possible direction.
Layer probing
Logistic regression probes (5-fold CV) are fit on each layer's activations to predict valence (positive vs. negative). The top-5 layers by accuracy are the multi-layer steering targets.
Steering
At inference, the block's forward method is monkey-patched (see above) to add α × v_l to its output. α > 0 steers toward positive affect; α < 0 toward negative. Multi-layer steering patches the top-5 layers simultaneously. Evaluation uses CLAP cosine similarity to "happy music" minus "sad music" text anchors as an automated valence proxy.
Finding 1 — Mood is linearly encoded in the middle layers
Probe accuracy peaks at layer 11 (88.3%), with a broad encoding window across layers 4–11 — roughly 17–46% of network depth. All 24 layers exceed chance (50%).
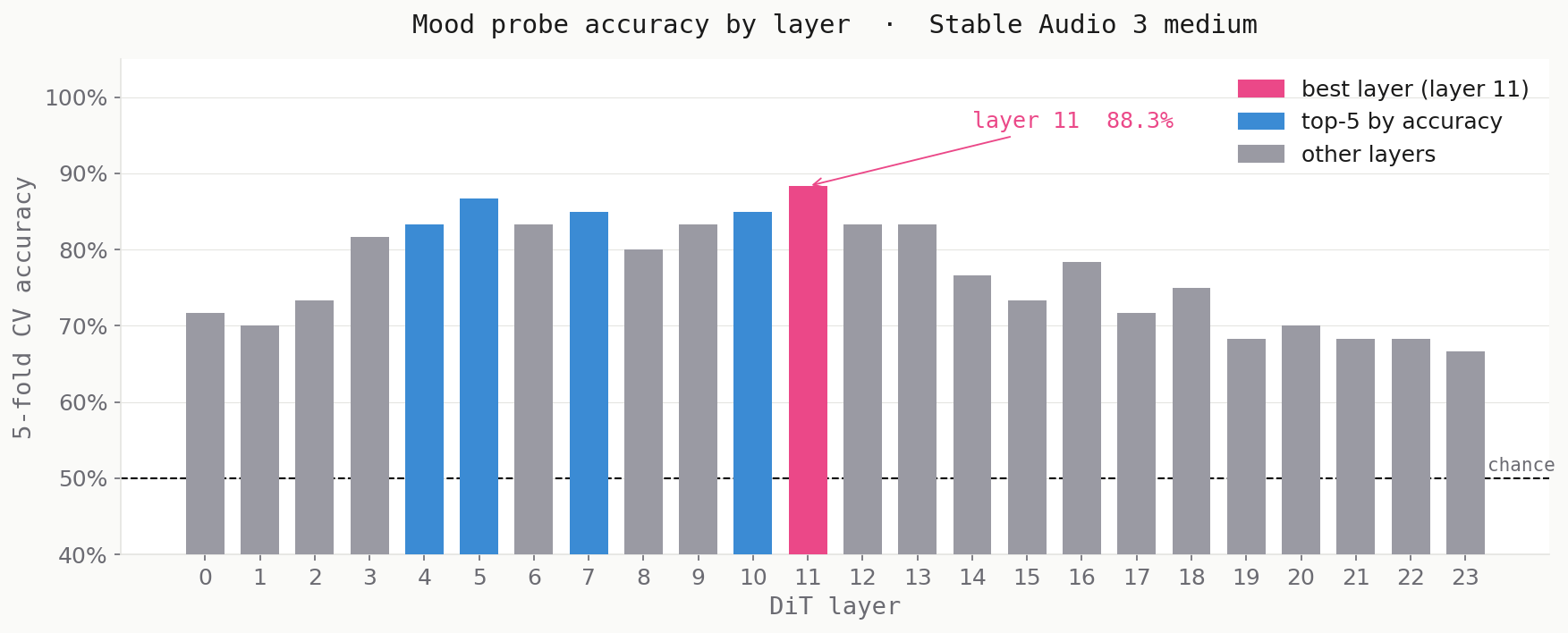
This mirrors the emotion geometry finding in LLMs: affective content is encoded in the middle layers, not in early feature-extraction or late generation-committed layers. The window here (17–46% of depth) is consistent with the 33–44% window in Qwen3-8B [5] and with concurrent findings in other audio DiT architectures [3]. The consistency across architectures and modalities is the interesting signal: this appears to be a general property of Transformer residual streams, not a model-specific artefact.
One caveat: all layers exceed chance by a substantial margin, which suggests mood information is distributed throughout the network rather than sharply localised. The probe accuracy profile reflects where the information is most linearly concentrated, not where it exclusively lives.
Finding 2 — Multi-layer steering shifts mood perceptibly across 10 genres
Steering the top-5 layers simultaneously produces clear perceptible shifts. Each sweep below uses the same seed and same prompt — only α changes.
⚠ at α = −20 some genres produce a song-ending artifact — decaying notes, fading dynamics, silence. See Finding 3.
⚠ at α = −20 some genres produce a song-ending artifact — decaying notes, fading dynamics, silence. See Finding 3.
⚠ at α = −20 some genres produce a song-ending artifact — decaying notes, fading dynamics, silence. See Finding 3.
⚠ at α = −20 some genres produce a song-ending artifact — decaying notes, fading dynamics, silence. See Finding 3.
⚠ at α = −20 some genres produce a song-ending artifact — decaying notes, fading dynamics, silence. See Finding 3.
⚠ at α = −20 some genres produce a song-ending artifact — decaying notes, fading dynamics, silence. See Finding 3.
⚠ at α = −20 some genres produce a song-ending artifact — decaying notes, fading dynamics, silence. See Finding 3.
⚠ at α = −20 some genres produce a song-ending artifact — decaying notes, fading dynamics, silence. See Finding 3.
⚠ at α = −20 some genres produce a song-ending artifact — decaying notes, fading dynamics, silence. See Finding 3.
⚠ at α = −20 some genres produce a song-ending artifact — decaying notes, fading dynamics, silence. See Finding 3.
Finding 3 — Three qualitative observations
The mood direction conflates valence and arousal
A consistent pattern across all 10 genres: negative α reduces rhythmic density and energy; positive α increases it. At α = −10, most genres produce slower, sparser textures — fewer notes per bar, longer sustains, more silence. At α = +10, the same prompt yields busier, denser arrangements. The prompt hasn't changed. Only the internal direction has.
This means the extracted direction is better described as a positive/negative affect direction rather than a pure valence direction. It captures a mixture of valence (harmonic tone: major vs. minor) and arousal (energy: dense vs. sparse) — both axes of the circumplex model of affect [7]. This is expected: in music training data, happy tracks tend to be more energetic and sad tracks slower, so a mean-difference vector computed from happy/sad pairs will inevitably pick up both dimensions together. The same entanglement appeared in Qwen3-8B in my previous post.
Disentangling the two axes — extracting orthogonal valence and arousal directions and testing whether they can be controlled independently — is the most important next experiment.
The "song ending" artifact at extreme negative α
At α = −20, several genres (particularly piano, strings, ambient) produce audio that resembles the final bars of a piece — decaying notes, fading dynamics, a sense of resolution and closure rather than active music.
Genre-dependent steering effectiveness
Quantified via CLAP valence scores (cosine similarity to "happy music" minus "sad music" text anchors):
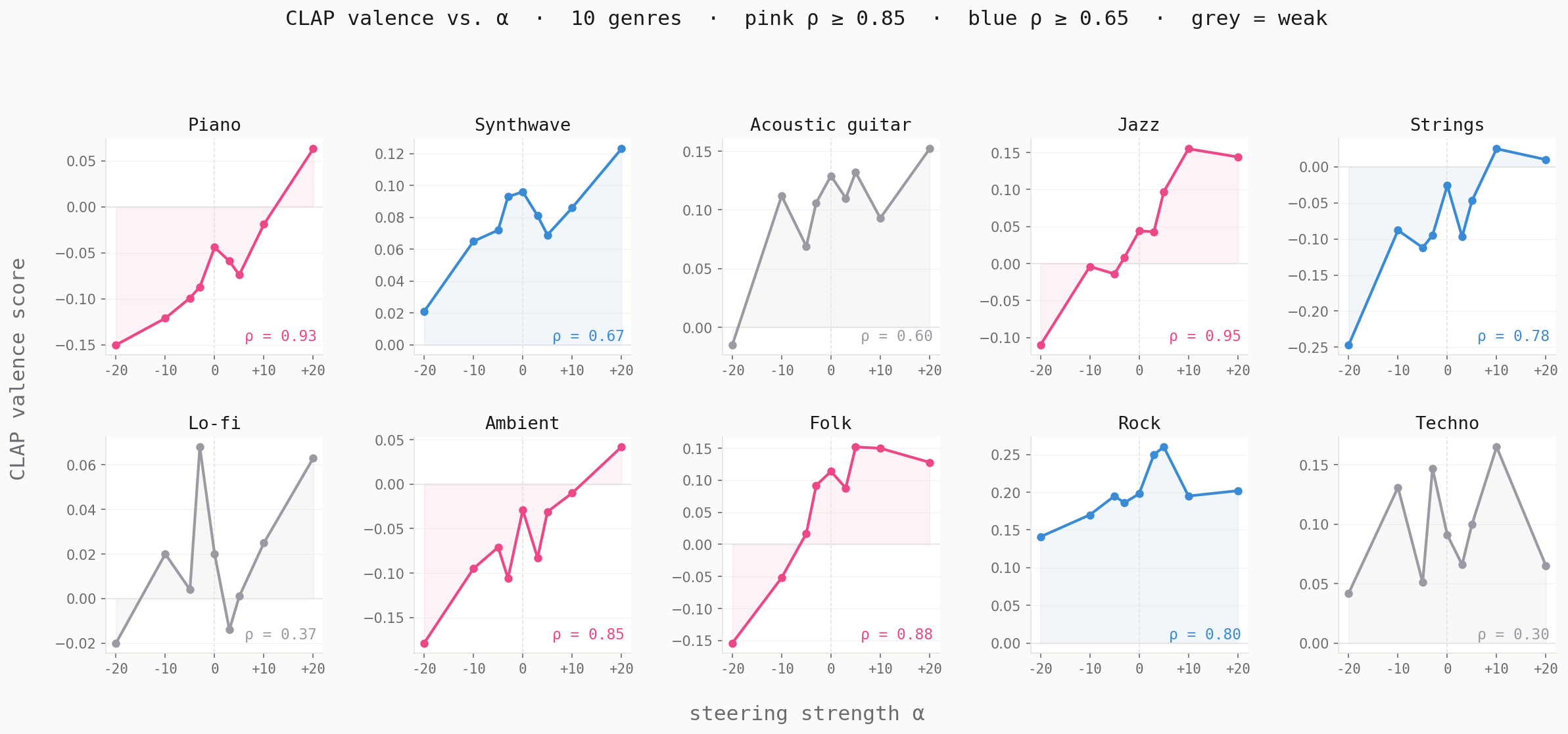
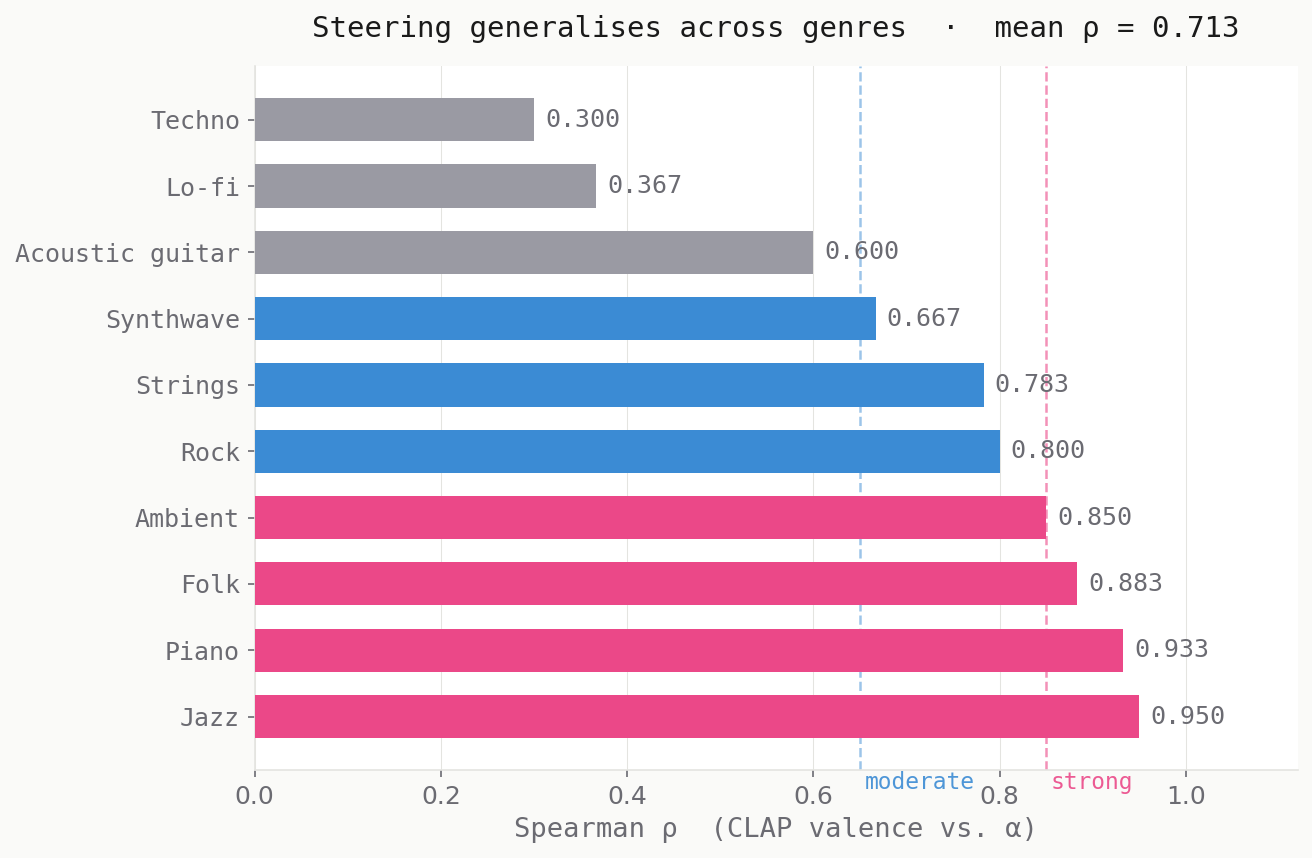
Harmonic genres (jazz ρ = 0.950, piano ρ = 0.933, folk ρ = 0.883, ambient ρ = 0.850) show the strongest signal. These genres rely on harmonic content — chord progressions, melodic phrasing, tonal colour — which maps directly onto what the mood direction was trained to separate (major vs. minor, bright vs. dark).
Rhythmic/electronic genres (techno ρ = 0.300, lo-fi ρ = 0.367) show weak CLAP signal. This doesn't necessarily mean steering isn't working perceptually — it means CLAP assigns high positive valence to these genres by default, so even at α = −20 the CLAP score stays positive. The metric is biased for these genres. A human listening study would likely reveal more effect than CLAP reports.
Discussion
Connection to the LLM emotion geometry
The probe accuracy profile — peaking in layers 4–11 out of 24, roughly 17–46% of depth — closely mirrors the causal window in Qwen3-8B (33–44%). In both architectures, middle layers are the representational home of affective content. The linear representation hypothesis appears to hold across modality: whether the model generates text tokens or continuous audio latents, mood emerges as a decodable linear direction in the residual stream.
The valence–arousal entanglement problem
The most important limitation is also the most theoretically interesting observation: the mean-difference direction captures a joint valence+arousal signal. This is consistent with the circumplex model [7] — in music training data these dimensions are correlated — but it limits the precision of the intervention. To get true valence control without energy change (or vice versa), you'd need to extract two orthogonal directions from contrastive pairs designed to vary one dimension while holding the other constant: e.g., high-energy sad music vs. high-energy happy music for pure valence; high-energy vs. low-energy music in the same valence for pure arousal.
CLAP as an evaluator: strengths and biases
CLAP provides automated, scalable evaluation but is systematically biased for rhythmic genres that it associates with positive energy. Future work should cross-reference with at least one other audio-language model and include a human perceptual study with blind α-shuffled listening. The CLAP results are best read as a lower bound on steering effectiveness for rhythmic genres.
Conclusion
Stable Audio 3 encodes a positive/negative affect direction as a linearly decodable vector in its DiT residual stream. Layer 11 achieves 88.3% probe accuracy separating happy from sad activations, within a broad encoding window at layers 4–11 (17–46% of network depth). Multi-layer steering across the top-5 layers shifts generated audio perceptibly across 10 musical genres — mean Spearman ρ = 0.713 against CLAP valence — with the same prompt and same weights.
Three qualitative findings accompany the quantitative result. The extracted direction conflates valence and arousal — negative α consistently reduces rhythmic density, not just harmonic tone. Extreme negative α produces song-ending artifacts, suggesting the model has learned that musical finality carries negative affect. Steering is strongest in harmonic genres and weakest in rhythmic ones, partly because CLAP is a biased evaluator for high-energy electronic music.
One practical finding that stands on its own: @torch.compile silently breaks register_forward_hook. Method monkey-patching is the correct approach for mechanistic interpretability on compiled models, and worth knowing before you spend hours debugging zero-effect steering.
The mood map is real, linearly encoded, and steerable. It lives in layers 4–11, it knows what the end of a song sounds like, and it conflates how sad something is with how quiet it gets — because in music training data, those things go together.
Related Work
Concurrent independent work [3] studies activation steering in audio diffusion models and reaches qualitatively similar conclusions about the localisability of musical concepts in Transformer layers. Earlier work on steering autoregressive music models [4] and a growing body of SAE-based audio interpretability work provide additional context. The emotion-geometry LLM literature [1, 5, 6] provides the conceptual framing for the cross-modal comparison.